The Etruscan Room: Using Images to Pose Internet Queries
Abstract. Visual thinking has a long tradition. Today, however, access to general information on the Internet largely requires the use of textual language. We have developed a computer program that combines artistic and technological considerations to help visual thinkers use standard search engines to find information. Called the Etruscan Room, the program adopts a metaphor for its design that goes back to a pre-Roman era. However, it also incorporates philosophical ideas exemplified by Renaissance painters. The program may be of interest not only to artists and technologists, but also to people who are unable to type or who have difficulty formulating textual queries because of aphasia.
Historical and Philosophical Motivation
In ancient Egyptian culture (3500 bce), tombs were designed in the form of underground houses, each with a system of rooms. The rooms typically contained all the objects belonging to the deceased, including food and all things useful for day-to-day life. Etruscan tombs of the classical period (500-300 bce) were similar to those of the Egyptians with some differences: some were painted with frescos of epic scenes, others with scenes of activities of everyday life, such as hunting, fishing, sports and feasts. In particular, some tombs in the north of Lazio (Cerveteri) were decorated with bas-reliefs engraved in slabs of tuff (a volcanic stone) representing the artisan tools of the dead person [Figure 1]. These sculptures were representations intended to illustrate the (past) world of the deceased and not intended to be part of a new underground life. The iconography was later integrated into Roman culture.

These frescos suggest that various communities dedicated themselves to different trades. This is exemplified in the tombs by the bas-reliefs of artisans' tools, which appear as professional symbols of the trades. The underground rooms seem to work as a Venn diagram of closed symbolic spaces containing objects related to particular crafts, which represent the activities associated with the rooms. The whole of these underground regions and their sculptures and pictures illustrate the history of the community.
If one considers these Etruscan rooms abstractly, one might imagine that all communities in the world are organized into a system of rooms, chambers connected together, some rooms containing others as in Chinese boxes, some imposing a social system.
This intuition might have been present in the minds of Italian painters in the sixteenth century. The Renaissance painters had a peculiarity that helped them conceive of history in a unique way: they were using images in order to understand nature. Piero della Francesca often represented standard religious iconographies by illustrating objects with the use of visual pyramids in which one vertex was inside the eye of the observer (behind the pupil, on the retina). Piero found through experiments that this observer image was upside down [Figure 2]. His representations reinforce the notion that the world can be analysed as a collection of rooms.

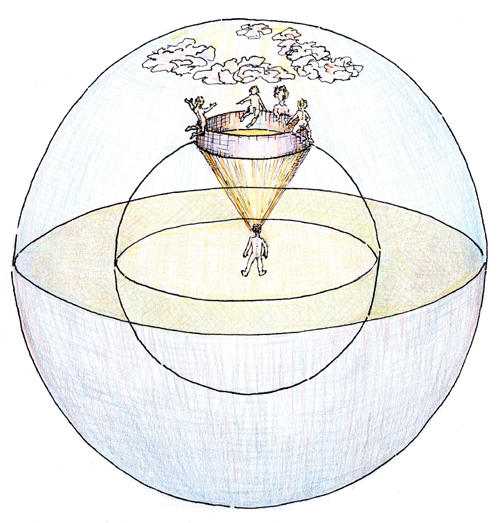
At the centre of the ceiling in the Camera degli Sposi (1465-74) in the Gonzaga ducal castle at Mantova, Andrea Mantegna painted an ‘architectonic eye,’ a sort of circular balcony from which the Duchess Isabella looks out [Figure 3]. Through it, the sky vault looks concave; this appearance is enhanced by a spiral of painted clouds. The observer can recognize in this representation the cosmological Ptolemaic model: a crystal globe surrounding our planet with the observer at the center [Figure 4]. The amazing aspect of this painting is that the ceiling is really concave. In fact, there is much evidence that suggests Mantegna conceived a design for a concave representation and not a Euclidean one.* The explicit visual representation of an observer situated at the centre of the cosmos with direct visual access to it all is suggestive of the computer program we sought to create.

An idea based on the same visual model inspired Sandro Botticelli's Mystic Nativity (1500, National Gallery, London), in which he represented the skyline in the background with an elliptical line converging at the centre, which delimits the base of a hemispherical sky vault [Figure 5]. This Ptolemaic cosmological vault looks naturalistic, with an everyday sky, under which we find the Holy Family.
Renaissance painters used an analogical iconic system with dramatic realism based on a scientific knowledge of vision, light and perspective. On the one hand, the representation of perspective had a scientific confirmation, and it introduced the possibility of rendering the Platonic-Christian conception of the cosmos with a Ptolemaic elliptical vault. On the other hand, realism and strong analogy augmented with iconic representations were demonstrating that the laws of vision and the Platonic conception could be fused together and serve as the interpretation keys to the world. We have tried to embody this spirit in the Etruscan Room computer program.

As was usual for most Renaissance painters, Antonello da Messina directed his work to religious iconography. One of these representations is of particular interest because its Ptolemaic perspective system involves the observer in an auto-referential system of perception. The painting Saint Jerome in His Study (c. 1475, National Gallery, London) involves the observer in its representation by means of a painted window opened in the wall of a building [Figure 6]. Looking through the window, the observer sees Saint Jerome working at his desk. This is inside a strange little working-box containing bookcases with many books; it is a sort of box or room of knowledge, an ante litteram database. This room is contained inside a nave which divides space into three parts contained in a building with windows in the back. Through the windows, it is possible to see the landscape outside the building, with mountains, trees, animals, rivers and towns. The landscape suggests what we call today the biosphere. The observer looking through the window opposite himself is aware that his observation point is part of the landscape seen through the windows in the back [Figure 7]. The observer understands that he himself, as well as Saint Jerome and the system of rooms inside the building, are part of the same context. This context is part of the Ptolemaic sphere which represents both a physical and Platonic-Christian model of the cosmos. Above all, the representation communicates the impossibility of Saint Jerome (who was a symbol of occidental knowledge at that time) mentally transcending the visual boundary of the Ptolemaic vault. It also suggests that even if humans are provided with the best database possible, there always remains a frontier between perception and knowledge. The frontier is set by the limits of physical perception imposed on humans by the fact that they belong to the physical world [Figure 8]. The observer, too, is inside the representation and looks to Saint Jerome, the model of the best mind in the world and the repository of encyclopaedic knowledge, who knows his limits in trying to go behind the Ptolemaic vault. The vault also represents the inexplicable ‘O’ concept, the meaning of infinity.



Only the mathematician Kurt Gödel has been able to describe in logical terms the limitations of the mind in representing and predicting the features of infinity in a logical and mathematical context [11]. He demonstrated with his famous incompleteness theorem the impossibility of circumscribing all the logical propositions of mathematics by means of a finite number of laws.
Antonello's painting seems to portray in a similar way, and very effectively, the limit of human perception in breaking the symbolic wall of the Ptolemaic globe. This metaphor, about the human limits in understanding the deepest meaning of the mind, is an old problem that can be found in ancient Greek philosophy.
The Etruscan Room
It might seem strange to be introducing a computer program through a discussion of the images of Renaissance painters, but let us consider the relationship between Antonello's picture of Saint Jerome's studio and the illustration in Figure 9. The computer monitor works as a window into a room in which a variety of different representations can be combined. There is an isomorphism between the elements in the studio and the elements on the monitor. The Etruscan Room program is a realization of this window and the room within it.**

There are two reasons for basing the program on the metaphor of Etruscan rooms.
- First, theories of visual representation generally embody technical goals that cannot be separated from the cultural domains in which they are conceived and to which they are directed. With the Etruscan room idea as our model, we can acknowledge this association.
- Second, when visual communication involves anthropological contexts, there must be a means of construction and composition for expressions in the language, and a theoretical basis for this can be helpful.
The Etruscan room model has some affinities with the Platonic conception of ‘category.’ The vitality of this model can find testimony in much of the mathematics and logic underlying contemporary computer applications.
The idea that a room could contain visual representations related to features of a specific topic of interest suggests to us the idea of a world composed of rooms, each with a specific set of visual features representing some human activity [Figure 10]. We planned a certain number of rooms, each represented by an icon. Each icon exemplifies a meaning of an object or of an action. Any combination of two or more images (and, in turn, rooms) has a metaphorical meaning which offers a new context of interest. With one hundred images of rooms it is possible to categorize hundreds of thousands of concepts and categories. Moreover, it is possible to formulate thousands and thousands of concepts never before foreseen.

In the main screen of our computer program, the rooms are represented by squares of 2 cm by 2 cm, each containing the image of a realm or of a domain associated with a realm (e.g., the realm of ‘city’ in Figure 11).*** When the user clicks on an icon, the corresponding realm is added to the query table at the bottom of the screen. A single click selects the realm. If the user clicks on the same icon twice, two copies of the image will appear in the query table, and meaning of the pair may be augmented with additional associated ideas such as those based on the plural of the singular case or additional generalizations. For example, one click on the ‘baby’ icon selects the realm of the child, but a pair of clicks adds the realms of ‘children’ and ‘descendants.’

The user can combine realms and domains without any restriction and thus build a visual metaphor for (in principle) any idea [Figure 12]. In the present version of the program, there are 108 icons. They are situated in a table on a browser web page for making Internet queries. These iconic buttons are intended to represent the most important categories of an encyclopaedia [Figure 13]. When the user clicks on images in the menu, they are copied onto a small area near the bottom of the screen, the query table of the Etruscan Room [Figure 14], which can contain up to five images. Clicking on the button marked ‘Show Possible Meanings’ opens a separate web page containing a submenu of topics corresponding to the selected images [Figure 15]. The user can select any of these labels corresponding to specific topic combinations in order to continue searching for information via an Internet search engine. In our current version, the user can transition seamlessly into a page of search engine results dynamically created by Google.




The user, working at the realms level can press one or more buttons to formulate a collection of concepts. Then, the user can test the various concepts associated with a realm to find both those he might have predicted and those he did not foresee.
Before describing some sessions with the program, let us say a few words about the potentiality of images in comparison with words for making queries on the Internet. In the most well-known search engine on the Internet, Google, the queries are linked to meanings in a statistical way, according to keyword occurrence statistics within the web. There are no guarantees that the answers will satisfy the user; it is apparent that in the queries with more than three words there is a dispersion of meaning when the search engine relates them in the page of search results.
In a system based on relations among images, the interpretation errors are different, and in some cases may be reduced. With one image there is usually a notable ambiguity by design: in order to support querying with metaphors, some general concepts must be associated with each icon. However, when two images are related together, the ambiguity can be greatly reduced, once the user makes a selection from the subtopic menu. The selection of three images (or more) typically reveals the complexity of a combination of realms.
Consider the graphic representation shown in Figure 16. If we describe the image using words, we need to formulate a complex proposition, articulated with three sub-propositions: ‘The frog jumps out of the water and tries to catch a dragonfly flying just above her.’ On the contrary, an image communicates the meaning of the scene immediately, without forcing the user to struggle to interpret it; this is because the grammatical analysis which would take place in the left brain has been avoided. The literal descriptions of the icons are very complex, requiring artificial constructions in written language. They require a segmentation of the meaning into several parts; on the contrary, with three icons we immediately perceive the meaning.

The experience of seeing corresponds directly to the capacity of images to illustrate complex concepts by means of an iconic system. The special challenge of good visual communication is to concentrate a complex conception in only one image; if this image is well designed, it can be both unambiguous and aesthetically pleasing.
Written, textual language requires that the user work relatively hard to bring words and concepts together in order to formulate a query that will be effective in capturing the topic of interest. In the human visual system, images run by ‘direct line’ from the retina of the eye to the visual cortex in the brain. They can be analyzed and understood in real time in a somewhat more direct manner than that required for understanding written text [13]. This suggests that designers create a world of visual associations and invite the user to use images in developing queries.
The Etruscan Room is a program that, in spite of using many images, does not give a feeling of complexity. It invites the user to press buttons almost as a game, stimulating his curiosity without any cerebral fatigue.
Icons and Menu
The system has been configured to open in a web page. The main screen shows a certain number of iconic buttons illustrating objects and actions in the world. We used two main criteria in designing the collection of images. The first was to provide individual icons that exemplify the most important concepts for anthropological contexts. The second has been to favour images that can also be interpreted with a metaphorical meaning. The user can select one button or multiple buttons; in the latter case, one obtains a metaphorical combination that expands exponentially the number of possible concept expressions.
Icons, when they are composed together, work in a manner somewhat similar to composition of characters in the Chinese language. Some of the icons are based on Egyptian hieroglyphics. However, they are drawn using a more realistic or ‘analogical’ style, and they are much less geometric in character. What is remarkable is that the application of Egyptian icons to current-day anthropological contexts is still appropriate, and their semantics fit the world of today surprisingly well.
As the user selects icons, they appear in the query table at the bottom of the screen. Submitting the set of selected icons by means of the ‘Show possible meanings’ button opens the submenu. From the more specific context thus established, the user can continue on to a search via keywords with the help of a standard search engine. The alternative meanings and combinations are presented as links so that the user can easily go directly to a search results page without any typing. Although the program is currently configured to work only with Google, it would be easy to have it work with other search engines, such as Yahoo!, Lycos, etc.
This program is very fast, pleasant and easy to understand. It has been built with a group of images distributed in realms and domains whose combinations give out thousands and thousands of meanings. Relating every image to corresponding meanings at the domain level would require a very large effort because of the many possible combinations of images. There are more than 10,000 possible pairs of images and more than one million triples of images. However, the combinations are not all of the same semantic relevance for queries, and really the project at the beginning has consisted of working out the meanings of the most general and practical interest. With this foundation in place, users can test other possible combinations in particular contexts and inscribe the meanings into the database. The meanings can be added for purposes of entertainment and exploration, or with the intent to make searches more efficient for users in particular topic areas.
On the basis of our earlier experience with the program Vedo-Vedi in a related genre (visual communication), we adopted the use of squares of 2 cm by 2 cm in the Etruscan Room. This implies that one or more features of a subject must be represented in a very small spatial area. Thus it is not possible to introduce much detail in the squares. Yet at same time, the image cannot be simplified too much because a schematic representation might be too close to the geometric style of Egyptian hieroglyphics, resulting in cryptic and undecipherable icons.
The methodology used to create the images has been to schematize realistic shapes from three dimensions, and then to use complementary colors which work together in creating volumetric effects. The images must be simple and at the same time not simplistic, giving the user the possibility of easy and unequivocal interpretation of the objects depicted. The perfect image in our context is one that communicates the meaning in a few seconds.
Extensibility and Universality of the System
The program does not impose any rigid ordering among the buttons in combining meanings. All the possible icon combinations refer, either explicitly or implicitly, to categories that the user illustrates by visual metaphors.
At this time we have identified only some of the more important combinations of icons in order to clarify the methodology to users. The system is built to give any user, in principle from any culture, the opportunity to devise associations and add new particular meanings before invoking an Internet search with Google. Over time, users' contributions could extend the database indefinitely and add new formulations to the encyclopaedia of the system, which others could use.
The only problem with such an open policy is that unscrupulous or careless users might pollute the database with inappropriate meanings. One solution may be to build a management structure over the editing of meanings, so that users could propose meanings that would then go through an approval process.
The universe of knowledge consists of a system of human-centered representations that are in a continuous process of transformation and redefinition. The Etruscan Room program provides a means to facilitate the association of image combinations with new meanings. These associations can then help users in the mental formulations required for querying an ever richer, ever-more complex World Wide Web.
When an idea for a new computer program is considered, its utility for people is a primary concern. In addition, it must go beyond the capabilities of existing programs and add new value. A possible confusion about the purpose of the Etruscan Room is that it might be intended as a replacement for the text-based query interfaces of Google and other search engines. Another possible worry might be that the use of images might tempt some users to engage in banal activities.
Our intent in devising the Etruscan Room has been to offer an alternative means for querying the web, a means in which the need to type is either eliminated or greatly reduced, and in which visual thinking is supported. Although most of a search engine's results are presented as text, many people can read but cannot type. Or they can type, but with great effort. For others, the Etruscan Room might serve as a language learning tool. Beginning with images, a language student can quickly retrieve text related to the images.
We hope that the Etruscan Room can lead to more effective access to information for many people. We also hope that it can encourage the development of new ideas and contribute to the causes of communication, democracy, science and improving the lives of people.
Images and Aphasia
There is another context of interest related to this program. People with certain types of aphasia, the loss of the ability to comprehend or produce language due to brain injury, may benefit from access to non-language-based computer interfaces. Although it was previously thought that aphasics suffer intellectual deficits, we know today that many aphasic patients have normal intellectual abilities [15]. Neurologist Oliver Sacks has observed that human relations among aphasics and others is highly dependent upon visual perception and that the entire brain collaborates in substituting grammatical functions with visual-cortex and right-brain functions [16]. Thus aphasics understand and express concepts related to emotions, melodies, mime and all those things that can be expressed by means of images and perceived through vision better than those concepts requiring words.
Many aphasic people have adopted a sort of vocabulary in which words are organized into categories of objects, people, events, emotions and moods [16]. It is possible that their categories could be linked to those used in the Etruscan Room. In this case, the range of interests of aphasics could be expanded to representations of virtual objects and logical relations among these images. The relations between images and concepts could be used in training activities to help them relearn the associations between grammar relations and literal meanings. The fact that the human brain has plastic faculties that can compensate for lost abilities suggests that it is possible the Etruscan Room program could help to stimulate a learning process to achieve rehabilitation more quickly. The Neurological Hospital at the University of Rome La Sapienza is testing the program for use with patients with damage to grammar-processing areas of the brain.
The Etruscan Room: Technical Aspects
The Etruscan Room program is implemented with a client-server architecture. The client uses JavaScript to handle interaction with the user within a browser. The server contains a repository of icons and associated meanings, and it hosts Perl scripts that can retrieve meanings and that can store new meanings when the program is used in editing mode.
The Etruscan Room can, in principle, work in many different languages. The current version works in English and Italian. For any given language, the meanings associated with icons and their combinations are stored in two separate files, one for the individual icons and one for their combinations. Each icon is permitted up to four independent keyword phrases for singular meanings and up to two additional keyword phrases for plural meanings. These numbers were chosen to balance the needs for generality (tending towards greater numbers) and simplifying user choices (tending towards smaller numbers). In addition, any combination of two to five icons can have up to four additional keyword phrases associated with it.
The list of meanings associated with each icon and each combination of icons has been designed to approximate as well as possible, given a finite time for the job, the ideal set. No doubt there are some inconsistencies in aspects of these meanings; users may sometimes find meanings they do not expect or fail to find meanings they do expect, and improvements are possible. (The editing facilities for the meanings lists are described below.)
When a user selects two icons to make a query and then asks to see the possible meanings, the system creates a new page with a menu of subtopic combinations as follows: (1) all the specifically provided meanings for the given combination of icons are listed, each as a separate option; (2) the keyword phrases for each of the icons are retrieved and combined, and each of these combinations is listed as a separate option. If some particular icon occurs more than once in a query, then its plural meanings (if any are registered in the dictionary) are included in the list of keyword phrases for the first occurrence of that icon.
The keyword lists for the icons in a query are combined using a mathematical operator known as the Cartesian product. Suppose that a query contains three distinct icons, and the first icon has two keyword phrases, the second icon has four keyword phrases, and the third icon has three keyword phrases. Then there will be 2 × 4 × 3 = 24 subtopic options listed for these.
The order in which the icons are listed in the query is significant. The combination of ‘woman-man’ is not automatically equivalent to the combination ‘man-woman.’ Although a search engine might consider these queries to be identical, by default, Google does not. The Etruscan Room preserves this aspect of the expressive power of Google queries by not automatically discarding the order in which query terms are given. In this regard, the meanings of combinations are different from what one might get from a scheme based on Venn diagrams. Venn diagrams express set combinations made using intersections, unions and complements, and intersections and unions are commutative (order independent) operations.
The intended end users of the Etruscan Room are people who wish to use images for making information queries in the Internet. However, there are additional features in the system provided for ‘editors.’ Editors are people who wish to add meanings to the individual icons or to the combinations of icons so that users who make queries can take advantage of those new meanings. The editing interface permits editors to specify up to four meanings for each combination, up to four meanings for each individual icon and up to two plural meanings for each individual icon. Meanings are stored on the server for future use. The files of meanings in each of the languages (currently only English and Italian) are separate and must be edited separately.
For research purposes, the program automatically logs each submenu selection by users. In the future, the information about which options were selected most frequently for each combination of icons might serve to reorder or reduce the menus of subtopics.
Discussion
There are many interesting questions one can consider regarding the relationship between visual representations and their corresponding meanings in the context of an Internet search. We consider a few of these here.
One question is ‘What factors are most important in determining the search results one gets during a session?’ At the end of a query with the Etruscan Room, the search results are a product of (a) the user's thinking, and thus the user's particular choice of query icons, (b) the meanings provided for each icon, (c) the way in which meanings are automatically combined in the Etruscan Room software, (d) the combination meanings explicitly provided, (e) the user's choice in the secondary menu of combination meanings, (f) the search engine's index, which is a combination of what documents it has processed in the past and how it processes them and (g) the search engine's query-processing mechanism. The Etruscan Room software is only responsible directly for (c), but together with its files of meanings it is responsible for (b), (c) and (d). One could argue that it is indirectly responsible for (a) because the program's array of icons suggests to the user the concepts that can be explored within it.
Another question regards the number of distinct concepts that can be specified using the program. One answer is a combinatorial one that has nothing to do with semantics. There are 108 different single-icon queries that can be posed. There are 1082 two-icon queries, 1083 three-icon queries and 1085 five-icon queries. The total of these is 14,830,601,148. While most of these will seem to be ‘odd’ combinations, we should note that a single such combination gives rise to a secondary menu with multiple choices. Although there will only be a handful of choices arising from a one-icon query, the number of secondary-menu choices from a single 5-icon query may easily be in the vicinity of 1000. Thus the number of distinct first-level and secondary-level queries that can be made using the program is approximately 1000 × 14 billion, which is 14 trillion. Some of these may then be processed by Google and result in multiple search results, although the Google search can also come up empty. This mathematical approach has ignored the issue of what we mean by a concept. A more nuanced answer, therefore, must state some definition for what a concept is and give some criteria for (a) distinguishing distinct concepts and (b) distinguishing individual concepts from what we might call compound concepts or combinations of concepts. One approach would be to use a standard dictionary, such as the Oxford English Dictionary or WordNet, as a reference concept base, with the understanding that each word or indexed entity in the reference represents one concept, and that any other ideas must be combinations of these concepts. We speculate that queries posed using the Etruscan Room program (using both the iconic and secondary menus) can be used to specify some small fraction, perhaps 1 or 2 percent, of these concepts. The trillions of other possible Etruscan Room queries, then, express combinations of some of these concepts.
Another interesting question is ‘How does the Etruscan Room compare with other systems for querying with images?’ Two very different approaches to posing queries with images are ‘image querying by contents’ and ‘iconic indexing’ [10]. In the former, an image or sketch is used as a query, and an information retrieval system tries to find an image on the web or in a database that is similar to it. One of the earliest systems of this type was QBIC, developed at IBM. The QBIC system can only be used to retrieve other images, not arbitrary information [17]. The second alternative approach, sometimes called iconic indexing, involves the selection or computation of a point within an image or map which then links to the document or other information to be retrieved. One implementation involves an ‘iconic/symbolic data structure’ [17]. Although this can be used to retrieve arbitrary information, it differs from the Etruscan Room in two fundamental respects. One is that the images themselves are not queries or combined to create queries. The other is that all the links between image points and documents must be built into the index structure in advance.
Notes
- *
- See also Mantegna's The Agony in the Garden (c. 1460, National Gallery, London) and Cristo morto nel sepolcro e tre dolenti (1490, Pinacoteca di Brera, Milano).
- **
- The Etruscan Room is hosted at the University of Washington, and the authors have made it available to Crossings readers.
- ***
- A realm is a relatively broad range of topics, whereas a domain is less broad. A realm typically includes multiple domains. The program's structure does not force a strict distinction between realms and domains. However, it can be helpful to the user to realize that the different icons represent sets of topics at varying levels of generality. We sometimes refer to the main page of icons as the ‘realms’ level and the page of possible meanings, presented textually, as the ‘domain’ level.
{kind=link}
Acknowledgements
The authors would like to express gratitude to Prof. Stefano Levialdi of the University of Rome for encouraging the collaboration between the authors.
References
- [1]
- Ashley, Jonathan, Myron Flickner, James Hafner, Denis Lee,
Wayne Niblack and Dragutin Petkovic. ‘The Query by Image
Content (QBIC) System.’ In Proceedings of the 1995
ACM SIGMOD International Conference on Management of Data, San
Jose, California, 22-25 May 1995. New York: ACM Press,
1995. 475.
- [2]
- Bernardelli, Carlo E. ‘The Evolution of Iconographic
Meaning across Anthropologic Contexts.’
In Representation: Relationship between Language and
Image: Palazzo dei Papi, Piazza San Lorenzo, Viterbo, Italy,
October 17-19, 1991. Edited by C. E. Bernardelli and
S. Levialdi. Singapore; River Edge, N.J.: World Scientific
Publishing, 1994. 51-70.
- [3]
- Bernardelli, Carlo E. L'immagine nel mondo della
rappresentazione. Rome: Ecotipi,
1997.
- [4]
- Bernardelli, Carlo E. Ipotesi per un'estetica
come metafora della scienza. Rome: Carucci,
1986.
- [5]
- Bernardelli, Carlo E. ‘Modello mentale e contesto
simbolico nella descrizione delle caratteristiche delle opere
d'arte con l'ausilio del computer.’ In Scritti e
immagini in onore di Corrado Maltese. Edited by Stefano
Marconi. Rome: Quasar, 1997.
- [6]
- Bernardelli, Carlo E. ‘Pensiero e linguaggio nella
dimensione dell'espressione artistica.’
In L'immagine, il segno, l'icona: gli impalpabili
spostamenti della rappresentazione, Atti del Convegno, Rome,
5-8 May 1989 Edited by Carlo E. Bernardelli. Rome:
Ecotipi, 1990.
- [7]
- Bernardelli, Carlo E. ‘Il sistema tolemaico come
modello cosmico.’ Prometeo 18.69 (2000):
52-67.
- [8]
- Bernardelli, Carlo E. ‘Visione e conoscenza: E
possibile comunicare concetti e organizzare l'informazione di
un dato contesto atraverso un sistema di
immagini?’ Prometeo 21.82 (2003):
30-37.
- [9]
- Fellbaum, Christiane, editor. WordNet: An Electronic Lexical
Database. Cambridge, Mass.: MIT Press, 1998.
- [10]
- Flickner, Myron, Harpreet Sawhney, Wayne Niblack, Jonathan Ashley, Qian Huang,
Byron Dom, Monika Gorkani, Jim Hafner, Denis Lee, Dragutin Petkovic, David Steele and
Peter Yanker.
‘Query by Image and Video Content: The QBIC System.’
Computer 28.9 (September 1995): 23-32.
- [11]
- Franzén, Torkel. Gödel's Theorem: An Incomplete Guide to its Use
and Abuse. Wellesley, Mass.: A.K. Peters, 2005.
- [12]
- Goodman, Nelson. Ways of
Worldmaking. Indianapolis, Ind.: Hackett,
1978.
- [13]
- Gregory, Richard L. Eye and Brain: The Psychology of Seeing. 5th ed.
Princeton, NJ: Princeton University Press, 1997.
- [14]
- Maltese, Corrado. Per una storia
dell'immagine. Roma: Bagatto, 1989.
- [15]
- National Aphasia Association. ‘Aphasia
Facts.’ http://aphasia.org/naa_ma
terials/aphasia_facts.html; accessed 9 June 2007.
- [16]
- Sacks, Oliver. ‘Recalled to Life -- A
Neurologist's Notebook.’ The New Yorker 81.34 (31 October
2005): 46.
- [17]
- Tanimoto, Steven. ‘An iconic/symbolic data
structuring scheme.’ In Pattern Recognition and
Artificial Intelligence: Proceedings of the Joint Workshop
on Pattern Recognition and Artificial Intelligence, held at
Hyannis, Massachusetts, June 1-3, 1976. Edited by
C. H. Chen. New York: Academic Press, 1976.
452-471.
- [18]
- Tanimoto, Steven and Carlo. E. Bernardelli,
‘Introducing New Nouns in a Children's Visual
Language.’ 1998 Symposium on Visual Languages:
September 1-4, 1998, Halifax, Nova Scotia, Canada. Los
Alamitos, Calif.: IEEE Computer Society,
1998. 74-75.
About the Authors
Carlo E. Bernardelli is a visual artist and epistemologist living in Rome, Italy. He formerly taught mathematics and painting, and he is the co-editor of Representation: Relationship between Language and Image, published by World Scientific in 1994.
Steven L. Tanimoto conducts research and teaching on visual languages, computer programming, image processing and artificial intelligence in educational systems at the University of Washington. He holds an A.B. in Visual and Environmental Studies from Harvard and a Ph.D. in Electrical Engineering from Princeton.